2022年码表49码排码图,惠泽社群排码表图
最后更新 :2021.11.20 19:13
2022年码表49码排码图
[机智]点赞再看,养成习惯!
背景
HTTP 协议基于文本传输,字符编码将文本变为二进制,二进制编码将二进制变为文本。TCP 协议基于二进制传输,数据读取时需要处理字节序。本文将介绍常见的字符编码、二进制编码及字节序,并一探 Golang 中的实现。
字符编码
引言:如何把“Hello world”变成字节?
Step1:得到要表示的全量字符(字符表)Step2:为每个字符指定一个整数编号(编码字符集)Step3:将编号映射成有限长度比特值(字符编码表)
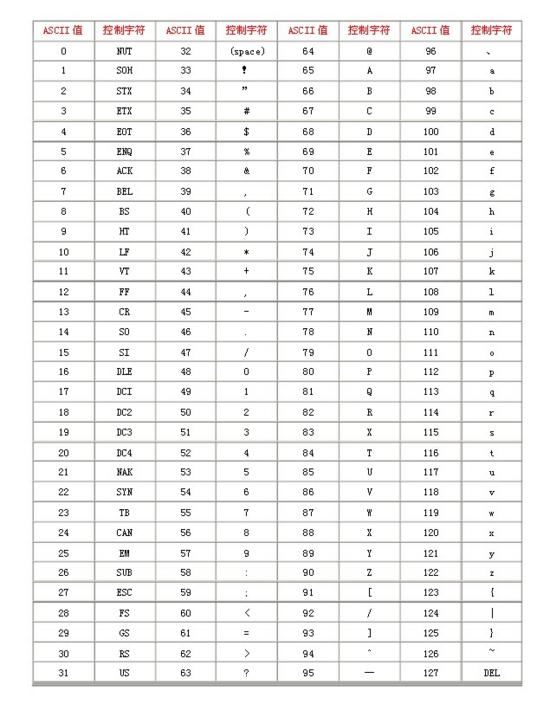
字符是各种文字和符号的总称,包括各文字、标点符号、图形符号、数字等。全世界共使用 5651 种语言,其中使用人数超过 5000 万的语言有 13 种,每种语言有自己的字符。汉语中,一个汉字就是一个字符。英语中,一个字母就是一个字符。甚至看不见的也可以是字符(如控制字符)。 字符的即为字符表 ,如英文字母表,数字表。ASCII 码表中一共有 128 个字符。
编码字符集(CCS:Coded Character Set)
为字符表中的每个字符指定一个编号( 码点,Code Point ),即得到编码字符集。常见有 ASCII 字符集、Unicode 字符集、GB2312 字符集、BIG5 字符集、 GB18030 字符集等。ASCII 字符集中一共有 128 个字符,包括了 94 个可打印字符(英文大小写字母 52 个、数字 10 个、西文符号 32 个)和 34 个控制符或通信专用字符,码点值范围为 [0, 128) ,如下图所示。Unicode 字符集是一个很大的,现有容量将近 2^21 个字符,码点值范围为 [0, 2^20+2^16) 。
ASCII字符编码表
字符编码表(CEF:Character Encoding Form)
编码字符集只定义了字符与码点的映射,并没有规定码点的字节表示方式。由于 1 个字节可以表示 256 个编号,足以容纳 ASCII 字符集,因此 ASCII 编码的规则很简单:直接将码点值用 uint8 表示即可 。对于 Unicode 字符集,容纳 2^21 至少需要 3 字节。可以采用类似 ASCII 的编码规则: 直接将编码点值用 uint32 表示即可,这正是 UTF-32 编码 。
这种一刀切的定长编码方式虽然简单粗暴,弊端也很明显: 对于纯英文文本,UTF-32 编码空间占用将是 ACSII 编码的 4 倍 ,造成极大的空间浪费,几乎没什么人用。有没有更优雅的解决方案?当然,这就是 UTF-8 和 UTF-16,两种当前比较流行的 Unicode 编码方式。
UTF-8
历史告诉我们,成功的设计往往具有包容性。UTF-8 是一个典型,漂亮的实现了 对 ASCII 码的向后兼容 ,以保证可以被大众接受。UTF-8 是目前互联 上使用最广泛的一种 Unicode 编码方式,它的更大特点就是可变长,随码点变换长度(从 1 字节到 4 字节)。 text
大道至简,优雅的设计一定是简单的,UTF-8 的编码规则也诠释了这一点。编码规则如下:
=127(U+7F)的码点采用单字节编码,与 ASCII 保持一致;127(U+7F)的码点采用 N 字节(N 属于 2,3,4)编码,首字节的前 N 位为 1,第 N+1 位为 0,剩余 N-1 个字节的前两位都为 10,剩下的二进制位使用字符的码点来填充。
其中(U+7F)表示 Unicode 的十六进制码点值,即 127。如果觉得编码规则抽象,结合下表更加清晰:
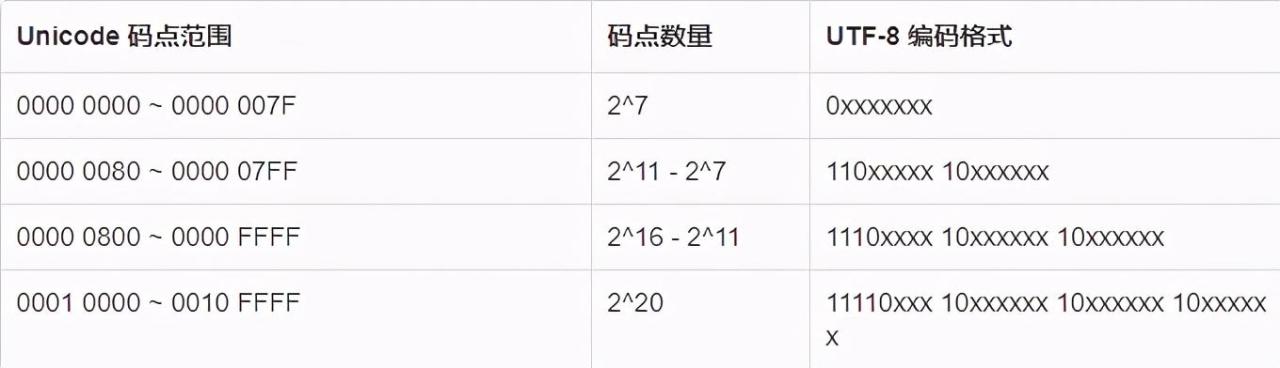
举个例子,如“汉”的 Unicode 码点是 U+6C49(110 1100 0100 1001),根据上表可得需要 3 字节编码,填充码点值后得到 0xE6 0xB7 0x89(11100110 10110001 10001001)。
根据编码规则,解码也很简单,关键是如何判断连续的字节数: 首字节连续 1 的个数即为字节数 。
需要一提的是, 在 MySQL 中,utf8 是“虚假的 utf8” ,更大只支持 3 个字节,如果建表时选择 CHARSET=utf8,会导致很多特殊字符和 emoji 表情都无法插入。 utf8mb4 才是“真正的 utf8” ,mb4 即 most bytes 4 。为什么 MySQL 中 utf8 更大只支持 3 字节?历史原因,在 MySQL 刚开发那会儿,Unicode 空间只有 2^16,Unicode 委员会还在做 “65535 个字符足够全世界用了”的美梦呢。
UTF-16
在 C/C++ 中遇到的 wchar_t 类型或 Java 中的 char 类型,这些类型占内存两个字节,因为 Unicode 中常用的字符都处于 [U+0, U+FFFF] (基本平面)的范围之内,因此 两个字节几乎可以覆盖大部分的常用字符 ,这正是 UTF-16 编码的一个前提。
相比 UTF-32 与 UTF-8, UTF-16 编码是一个折中:小于(U+FFFF)2^16 的码点(基本平面)使用 2 字节编码,大于(U+FFFF)2^16 的码点(辅助码点)使用 4 字节编码 。由于基础平面空间会占用 2 字节的所有比特位,无法像 UTF-8 那样留有“10”前缀。那么问题来了: 当我们遇到两个节时,如何判断是 2 字节编码还是 4 字节编码?
UTF-16 的编码的另一个前提: 在基本平面内, [U+D800, U+DFFF] 是一个空段(空间大小为 2^11) ,这些码点不对应任何字符。因此,这个空段可以用来映射辅助平面的字符。
辅助平面容量为 2^20,至少需要 20 个二进制位,UTF-16 将这 20 个二进制位分成两半,前 10 位映射在 U+D800 到 U+DBFF(空间大小 2^10),称为 高位 (H),后 10 位映射在 U+DC00 到 U+DFFF(空间大小 2^10),称为 低位 (L)。
映射方式采用线性映射。Unicode3.0 中给出了辅助平面字符的转换公式:
H = Math.floor((c-0x10000) / 0x400) + 0xD800
L = (c – 0x10000) % 0x400 + 0xDC00
也就是说,一个辅助平面的码点,被拆成两个基本平面的空段码点表示。如果双字节的值在 [U+D800, U+DBFF] 中,则要和后续相邻的双字节一同解码。具体编码规则为:
= (U+FFFF)的码点采用双字节编码,直接将码点使用 uint16 表示; (U+FFFF)的码点采用 4 字节编码,作差计算码点溢出值,将溢出值用 uint20 表示后,前 10 位映射到 [U+D800, U+DBFF] ,后 10 位映射到 [U+DC00, U+DFFF] ;
小结: 定长编码的优点是转换规则简单直观,查找效率高,缺点是空间浪费,以及不可扩展。如果 Unicode 字符集进一步扩充,UTF-16 和 UTF-32 都将不可用,而 UTF-8 具有更强的可扩展性。
Golang 中字符编码
不像 C++、Java 等语言支持五花八门的字符编码,Golang 遵从“大道至简”的原则: 全给老子用 UTF-8 。所以 go 程序员再也不用担心乱码问题,甚至可以用汉字和表情包写代码,string 与字节数组转换也是直接转换,十分酸爽。
func TestTemp(t *testing.T) { 打工人的问候()}func 打工人的问候() { 问候语 := “早安,打工人:grin:” fmt.Println(问候语) bytes := []byte(问候语) fmt.Println(hex.EncodeToString(bytes))}// 执行结果–早安,打工人:grin:e697a9e5ae89efbc8ce68993e5b7a5e4babaf09f9881
值得一提的是,Golang 中 string 的底层模型就是字节数组,所以类型转换过程中无需编解码。也因此, Golang 中 string 的底层模型是字节数组,其长度并非字符数,而是对应字节数 。如果要取字符数,需要先将字符串转换为字符数组。 字符类型(rune)实际上是 int32 的别名,即用 UTF-32 编码表示字符 。
func TestTemp(t *testing.T) { fmt.Println(len(“早”)) // 3 fmt.Println(len([]byte(“早”))) // 3 fmt.Println(len([]rune(“早”)) // 1}// rune is an alias for int32 and is equivalent to int32 in all ways. It is// used, by convention, to distinguish character values from integer values.type rune = int32
再看一下 go 中 utf-8 编码的具体实现。首先获取字符的码点值,然后根据范围判断字节数,根据对应格式生成编码值。如果是无效的码点值,或码点值位于空段,则返回 U+FFFD (即 �)。解码过程不再赘述。
// EncodeRune writes into p (which must be large enough) the UTF-8 encoding of the rune.// It returns the number of bytes written.func EncodeRune(p []byte, r rune) int { // Negative values are erroneous. Making it unsigned addresses the problem. switch i := uint32(r); { case i = rune1Max: p[0] = byte(r) return 1 case i = rune2Max: _ = p[1] // eliminate bounds checks p[0] = t2 | byte(r6) p[1] = tx | byte(r)&maskx return 2 case i MaxRune, surrogateMin = i && i = surrogateMax: r = RuneError fallthrough case i = rune3Max: _ = p[2] // eliminate bounds checks p[0] = t3 | byte(r12) p[1] = tx | byte(r6)&maskx p[2] = tx | byte(r)&maskx return 3 default: _ = p[3] // eliminate bounds checks p[0] = t4 | byte(r18) p[1] = tx | byte(r12)&maskx p[2] = tx | byte(r6)&maskx p[3] = tx | byte(r)&maskx return 4 }}const( t1 = 0b00000000 tx = 0b10000000 t2 = 0b11000000 t3 = 0b11100000 t4 = 0b11110000 t5 = 0b11111000 maskx = 0b00111111 mask2 = 0b00011111 mask3 = 0b00001111 mask4 = 0b00000111 rune1Max = 17 – 1 rune2Max = 111 – 1 rune3Max = 116 – 1 RuneError = ‘\uFFFD’ // the “error” Rune or “Unicode replacement character”)// Code points in the surrogate range are not valid for UTF-8.const ( surrogateMin = 0xD800 surrogateMax = 0xDFFF)二进制编码
引言:HTTP 是怎么传输二进制数据的?
Step1:定义字符集;Step2:将二进制数据分组;Step3:将每组映射为字符;
字符编码是「文本」变为「二进制」的过程,那如何将任意「二进制」变为「文本」?答案是进行二进制编码,常见有 Hex 编码与 Base64 编码。
显然 不能按字符编码直接解码 ,因为字符编码的结果二进制是满足编码规律的,而非「任意」的,非法格式进行字符解码会出现乱码(比如对 0b11xxxxxx 进行 UTF-8 解码)。
Hex 编码
Hex 编码是最直观的二进制编码方式,所见即所得。上文中的十六进制表示就是用的 Hex 编码。规则如下:
Hex 字符集为 0123456789abcdef ;每 4bit 为 1 组(2^4=16);每组映射为一个 Hex 字符;
计算机中二进制数据都是以字节为单位存储的,1 个字节 8bit,不会出现无法被 4 整除的情况。
每个字节编码为 2 个 Hex 字符,即编码后的字符数是原始数据字节数的 2 倍。 在 ASCII 或 UTF-8 编码下,存储 Hex 结果字符串需要的空间是原始数据的 2 倍,存储效率为 50%。
Base64 编码
Base64 编码,顾名思义,是基于 64 个字符进行编码。规则如下:
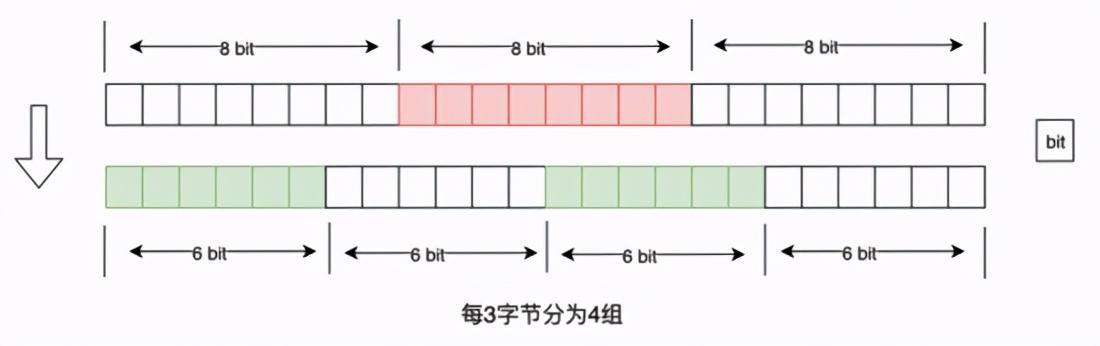
Base64 字符集(以标准 Base64 为例, 26 大写, 26 小写, 10 数字, 以及 + 、 / )为 ABC…YZabc…yz012…89+/ ;每 6bit 为一组(2^6=64),即 每 3 个字节为 4 组 ;每组映射为一个 Base64 字符;
如果要编码的二进制数据不是 3 的倍数,最后会剩下 1 个或 2 个字节怎么办? 标准编码(StdEncoding) 会先在末尾用 0x00 补齐再分组,并将最后 2 个或 1 个 6bit 分组(全为 0 填充)映射为’=’,表示补齐的 0 字节数量。
举个例子,以 0x12 34 ab cd
编码为标准 base64 为例:
不足 3 的倍数,先用两个 0 字节补齐 — 0x12 34 ab cd 00 000×12 34 ab 编码为 EjSr0xcd 00 00 二进制为 0b1100 1101 0000 0000 0000 0000 ,分为 4 组后为 110011 010000 000000 000000 ,编码结果为 zQ==最终编码结果为 EjSrzQ==
解码过程注意末尾字节的处理即可,此处不再赘述。
EjSrzQ== — 0x12 34 ab cd 00 00 — 0x12 34 ab cd
标准编码中编码结果字符长度一定是 4 的倍数,且是原始数据字节数的 4/3 倍,因为会将字节数据补齐至 3 的倍数,每 3 个字节编码为 4 个字符。 在 ASCII 或 UTF-8 编码下,存储结果字符串需要的空间是原始数据的 4/3 倍,存储效率为 75% 。
根据字符集的不同,Base64 编码有几个变种,除了标准编码(StdEncoding),常见的还有 URL 编码(URLEncoding)、原始标准编码(RawStdEncoding)以及原始 URL 编码(RawUrlEncoded)。
简单来说,Raw 指的是无 Padding,URL 指的是用 – 和 _ 取代编码结果中 的 url 关键字 + 和 / 。不妨参考 Golang 中 encoding/base64 包中的描述:
// StdEncoding is the standard base64 encoding, as defined in// RFC 4648.var StdEncoding = NewEncoding(*encodeStd*)// URLEncoding is the alternate base64 encoding defined in RFC 4648.// It is typically used in URLs and file names.var URLEncoding = NewEncoding(*encodeURL*)// RawStdEncoding is the standard raw, unpadded base64 encoding,// as defined in RFC 4648 section 3.2.// This is the same as StdEncoding but omits padding characters.var RawStdEncoding = StdEncoding.WithPadding(*NoPadding*)// RawURLEncoding is the unpadded alternate base64 encoding defined in RFC 4648.// It is typically used in URLs and file names.// This is the same as URLEncoding but omits padding characters.var RawURLEncoding = URLEncoding.WithPadding(*NoPadding*)
与标准编码不同的是, 原始编码中,字节数不足 3 的倍数时不会补齐字节数 ,采用如案:
如果剩余 1 字节,则左移 4bit 后转换为 2 字符;如果剩余 2 字节,则左移 2bit 后转化为 3 字符;
即 原始编码方案中,结果字符串长度可以不是 4 的倍数 。
最后,聪明的你一定已经发现了,Hex 编码可以看成“Base16 编码”。随着字符数量的增加,存储效率也随之增加。如果有“Base256”编码,存储效率岂不就 100%了?很遗憾,主流字符编码中,单字节能表示的可打印字符只有 92 个。通过扩充多字节字符,或用组合字符实现 base256 意义不大。
Golang 中的二进制编码
看一下 Golang 中 Base64 编码的实现。首先通过 EncodedLen确定结果长度,生成输出 buf ,然后通过 Encode将编码结果填充到 buf 并返回结果字符串。
// EncodeToString returns the base64 encoding of src.func (enc *Encoding) EncodeToString(src []byte) string { buf := make([]byte, enc.EncodedLen(len(src))) enc.Encode(buf, src) return string(buf)}
如前述,标准编码和原始编码(无 Padding)的结果长度不同:如果需要 Padding,直接根据字节数计算即可,反之则需要根据 bit 数计算。
// EncodedLen returns the length in bytes of the base64 encoding// of an input buffer of length n.func (enc *Encoding) EncodedLen(n int) int { if enc.padChar == *NoPadding* { return (n*8 + 5) / 6 // minimum # chars at 6 bits per char } return (n + 2) / 3 * 4 // minimum # 4-char quanta, 3 bytes each}
Encode实现了编码细节。首先遍历字节数组,将每 3 个字节编码为 4 个字符。最后处理剩余的 1 或 2 个字节(如有):首先使用移位运算进行 0bit 填充,然后进行字符转换。如前述,无 Padding 时,剩下 1 字节对应 2 字符,剩下 2 字节对应 3 字符,即至少会有 2 字符。最后在 switch 代码段中,根据剩余字节数填充第 3 个字符和 Padding 字符(如有)即可。
func (enc *Encoding) Encode(dst, src []byte) { if len(src) == 0 { return } // enc is a pointer receiver, so the use of enc.encode within the hot // loop below means a nil check at every operation. Lift that nil check // outside of the loop to speed up the encoder. _ = enc.encode di, si := 0, 0 n := (len(src) / 3) * 3 for si n { // Convert 3x 8bit source bytes into 4 bytes val := uint(src[si+0])16 | uint(src[si+1])8 | uint(src[si+2]) dst[di+0] = enc.encode[val18&0x3F] dst[di+1] = enc.encode[val12&0x3F] dst[di+2] = enc.encode[val6&0x3F] dst[di+3] = enc.encode[val&0x3F] si += 3 di += 4 } remain := len(src) – si if remain == 0 { return } // Add the remainingall block val := uint(src[si+0]) 16 if remain == 2 { val |= uint(src[si+1]) 8 } dst[di+0] = enc.encode[val18&0x3F] dst[di+1] = enc.encode[val12&0x3F] switch remain { case 2: dst[di+2] = enc.encode[val6&0x3F] if enc.padChar != *NoPadding* { dst[di+3] = byte(enc.padChar) } case 1: if enc.padChar != *NoPadding* { dst[di+2] = byte(enc.padChar) dst[di+3] = byte(enc.padChar) } }}字节序
引言:拿到两个字节,如何解析为整形?
Step1:明确字节高低位顺序Step2:按高低位权重计算结果
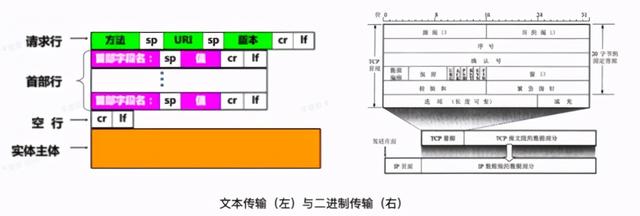
上述二进制编码主要用于文本传输,能不能不进行编码,直接传输二进制?当然可以,基于二进制传输协议,如 TCP 协议。那么什么是文本传输,什么是二进制传输?简单来说,文本传输,内容为文本,自带描述信息(参数名),如 HTTP 中的字段都以 KV 形式存在。二进制传输,内容为二进制, 以预先定义好的格式拼在一起 ,如 TCP 协议报文格式。
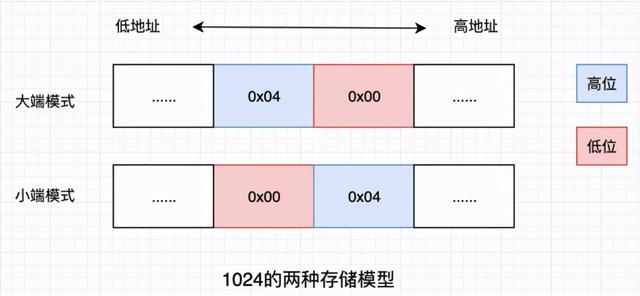
大端与小端
聊到二进制传输,一个避不开的话题是 字节序 。什么是字节序?假设读取到一个两字节的 uint16 0x04 0x00,如果从左往右(从高位往低位)解码,得到的是 1024,反过来(从低位往高位)解码则是 4,这就是字节序。 符合人类阅读习惯的(从高位往低位)是大端(BigEndian),反之为小端(LittleEndian)。
另一种大小端的定义:LittleEndian 将低序字节存储在低地址,BigEndian 将高序字节存储在低地址。理解起来有些抽象,本质上是一致的。
为什么会有小端字节序,统一都用大端不好么?
计算机不这么想,因为计算机中计算都是从低位开始的,电路先处理低位字节效率比较高。但是,人类还是习惯读写大端字节序。所以, 除了计算机的内部处理,其他的场合几乎都是大端字节序,比如 络传输和文件储存。
那什么时候程序员需要进行字节序处理呢?当多字节整形(uint16,uint32,uint64)需要和字节数组互相转换时。 字节数组是无字节序的,客户端写入啥,服务端就读取啥,不会出现逆序,写入和读取无需考虑字节序,这点大可放心 。 只有当多字节整形和字节数组互转时必须指明字节序。
Golang 中的字节序
以 uint16 与字节数组互转为例,看一下 Golang 中 encoding/binary 包中的字节序处理与实现。可见实现并不复杂,注意字节顺序即可。
func TestEndian(t *testing.T) { bytes := make([]byte, 2) binary.LittleEndian.PutUint16(bytes, 1024) // 小端写 — 0x0004 binary.BigEndian.PutUint16(bytes, 1024) // 大端写 — 0x0400 binary.LittleEndian.Uint16(bytes) // 小端读 — 4 binary.BigEndian.Uint16(bytes) // 大端读 — 1024}func (littleEndian) PutUint16(b []byte, v uint16) { _ = b[1] // early bounds check to guarantee safety of writes below b[0] = byte(v) b[1] = byte(v 8)}func (bigEndian) PutUint16(b []byte, v uint16) { _ = b[1] // early bounds check to guarantee safety of writes below b[0] = byte(v 8) b[1] = byte(v)}func (littleEndian) Uint16(b []byte) uint16 { _ = b[1] // bounds check hint to compiler; see golang.org/issue/14808 return uint16(b[0]) | uint16(b[1])8}func (bigEndian) Uint16(b []byte) uint16 { _ = b[1] // bounds check hint to compiler; see golang.org/issue/14808 return uint16(b[1]) | uint16(b[0])8}实战:加解密中的编码与字节序
在加解密场景中,通常我们会对 明文 加密得到 密文 ,对密文解密得到明文。比如对密码 “123456” (明文)进行 对称加密 (如4)得到 “G7EeTPnuvSU41T68qsuc_g” (密文)。 明文和密文都是由可打印字符构成的文本 ,通常明文人类可直接阅读其含义(不考虑二次加密),密文需要解密后才能理解含义。
那么上述明文变成密文,期间经历了哪些编码过程呢?以加密为例:
将明文 “123456” 进行字符解码(如 UTF-8),得到 明文字节序列 0x31 32 33 34 35 36 ;将明文字节序列输入4 加密算法,输出 密文字节序列 0x1b b1 1e 4c f9 ee bd 25 38 d5 3e bc aa cb 9c fe ;将密文字节序列进行二进制编码(如 RawURLBase64),得到密文 “G7EeTPnuvSU41T68qsuc_g” ;
同理,将” G7EeTPnuvSU41T68qsuc_g” 解密成 “123456” 过程中,应与加密过程的编码方式对应:先进行 RawRULBase64 解码,再解密,最后再进行 UTF-8 编码。
加解密算法的输入输出都是字节序列,所以要将明文、密文与字节序列进行转换。有两点需要注意:
明文解码为明文字节序列,解码方式因场景而定 。对于多次加密场景(如对“G7EeTPnuvSU41T68qsuc_g”再次加密),明文是 Base64 编码得到的,建议采用一致的方式解码。虽然也可以直接进行 UTF-8 解码,但会使加解密流程设计变得复杂。密文字节序列编码为密文,必须用二进制编码,不能用字符编码 。使用字符编码会产生乱码(意味着数据丢失,无法逆向解码出原始数据)。上述密文序列密文序列进行 UTF-8 编码的结果是 �L���%8���˜�。
合规要求,加解密场景中应使用 硬件加密机 。通常硬件加密机提供 基于 TCP 的字节流通信方式 ,比如约定每次通信数据中的前 2 字节为数据长度,后面的为真实数据。发送时,需要将真实数据长度转为 2 字节拼在前面,接收时,需要先读取前两字节得到真实数据长度 N,再读取 N 字节得到真实数据。其中 长度与字节序列的转换需要 字节序:发送方和接收方的字节序处理保持一致 即可,比如全用大端。下面给出了数据发送的示例代码:
func (m *EncryptMachine) sendData(conn net.Conn, data []byte) error { // add length newData := m.addLength(data) // send new data return util.SocketWriteData(conn, newData)}func (m *EncryptMachine) addLength(data []byte) []byte { lengthBytes := make([]byte, 2) binary.BigEndian.PutUint16(lengthBytes, uint16(len(data))) return append(lengthBytes, data…)}
总结
编码虽然基础,但却容易出错,切莫眼高手低。希望本文能帮助大家进一步了解字符编码、二进制编码与字节序,避免踩坑。真诚点赞,手留余香。
以上就是与2022年码表49码排码图相关内容,是关于二进制的分享。看完惠泽社群排码表图后,希望这对大家有所帮助!
男孩姓乔取名字,开朗活泼的乔姓男宝宝名字

男孩姓乔取名字,开朗活泼的乔姓男宝宝名字。百家姓,家喻户晓的一部著作,其中包含了中华民族...
妍静的名字怎么样 静妍这个名字的寓意
妍静的名字怎么样 在给孩子取名时,名字的寓意、音韵、五行等因素往往是家长们重点考虑的。“妍静”这个名字,究竟怎么样呢?让我们来深入探讨一下。 妍,意为美丽、巧慧。静,代表安静、宁静,寓意着一种遇事能够静心静气、淡泊...
蝴蝶为什么来家里 蝴蝶为什么进家

蝴蝶翩跹入家门:探寻其不速之客的秘密在宁静的午后,或是温馨的傍晚,偶尔会有几只色彩斑斓的...
为什么起名琉璃 琉璃名字由来
琉璃这个名字在中国传统文化中有着 深厚的含义。 根据中华传统的姓名学理论, 琉璃作为一个女孩的名字, 蕴含着美丽、华贵的意义。 琉璃作为一种特殊的装饰材料,在古代建筑和器皿中广泛应用, 被视为珍贵和高尚的象征。 因...
属猴和龙相配婚姻如何 属猴和属龙配吗?
根据传统文化中的生肖配 对理论, 属猴和属龙被认为是非常相配的一对。 以下是根据搜索结果得出的分析: 生肖配对理论 在中国传统文化中, 生肖配对是一种流行的婚配吉凶预测方法, 认为某些生肖之间的组合更加和谐, 而其他组...
邓紫棋为什么改名(邓紫棋为什么改名gem)
邓紫棋为什么改名:艺名背后的故事与考量 邓紫棋,华语乐坛的璀璨明星,以其独特的嗓音和才华赢得了无数粉丝的喜爱。然而,近年来她决定改名,这一决定引起了广大粉丝和乐迷的关注和猜测。那么,邓紫棋为什么改名呢?本文将为您揭...
竺字怎么起名(林字怎么起名) 竺在名字中怎么读
根据竺字起名:传统与现代的融合 竺字作为一个传统的姓氏,在中国传统文化中有着深厚的历史和文化底蕴。随着社会的发展和文化的传承,竺字起名也逐渐成为了现代社会的一种时尚。本文将探讨如何根据竺字起名,提供一些思路和...
三个变爻 之卦是哪个

三个变爻的卦象,在易经六十四卦中是非常特殊的存在。在易经卜筮中,变爻代表着某种变化或者...
哪个领导属马(属马的领导适合的下属)

领导的马年生肖是很多人关注的话题,因为在传统文化中,生肖的影响力和象征意义极大。那么,哪...
属鸡生辰哪个好(生辰属鸡的命运好吗)

属鸡的人在农历每年的鸡年出生,其生辰可以分为阳历和阴历两种日期。很多人都会关注属鸡生...
重庆约会的地方 重庆情侣约会的餐厅有哪些

重庆约会的地方 重庆情侣约会的餐厅有哪些作者:魔尘埃更新日期:2023-05-26 19:02:44阅读...
2016股市预测易经 2016的股市

老铁们,大家好,相信还有很多朋友对于2016股市预测易经和易经2021年股市的相关问题不太懂,没...
罗塔牌免费占卜婚姻 塔罗牌免费测试婚姻

本篇文章给大家谈谈罗塔牌免费占卜婚姻,以及塔罗牌占卜免费测试婚姻对应的知识点,文章可能...
按生辰八字给宝宝起名 按生辰八字给宝宝起名叫什么

大家好,感谢邀请,今天来为大家分享一下按生辰八字给宝宝起名的问题,以及和新宝宝取名字要按...
六爻八卦阴阳怎么读 乾卦六爻怎么读

大家好,如果您还对六爻八卦阴阳怎么读不太了解,没有关系,今天就由本站为大家分享六爻八卦阴...
公司名称测吉凶,请帮忙给服装店选个名字(测吉凶)

提起公司名称测吉凶,大家都知道,有人问请帮忙给服装店选个名字(测吉凶),另外,还有人想问公司名...
办公室座位朝向风水(办公室座位坐东北朝西南风水)

多数人在公司上班都是坐在自己的办公桌前用电脑完成自己的工作,所以不论办公桌上摆放的物...
男人桃花充沛长什么样 - ?命犯桃花面相特征 - 运势网

有些人感叹,本来自身标准还能够,长相也算不上差,而有些人平平无奇,身旁异性缘强大。有些人命...
婚姻不顺的六种化解方法 感情不顺念什么咒挽回

人的婚姻没有所谓永远完美,它们都是一个个小矛盾和小美好堆砌起来的。有时候婚姻会陷入一...
79年属羊的命运怎么样,67年属羊人的命运

79年属羊的命运怎么样 问:1979年出生是什么命? 1979年为农历己未羊年,纳音为“天上火”,我们...
白羊女会轻易离婚吗,白羊女一旦离婚

白羊女会轻易离婚吗 1点星座 婚姻的重要性不言而喻,常言道男怕入错行,女怕嫁错郎。选择一...
二婚比头婚幸福的生肖,什么样的婚姻才是幸福的

二婚比头婚幸福的生肖 文/1点星座 现如今社会上的离婚律是越来越高,很多人年纪轻轻在结婚...
2022年生肖狗女的婚姻,2022年属狗男生婚姻

2022年生肖狗女的婚姻 生肖鸡女命今年遇到三吉三凶,位列最凶排名榜第六名,主要是因为灾煞...
农历几月猪命苦,2007年几月猪命苦

农历几月猪命苦鼠出门看天色,进门看眼色。政治敏感,善于察言观色。家懒外勤,好走好串门。先...
92年属猴五行属于什么命,1992年属猴是金命吗

92年属猴五行属于什么命 老师你好,最近比较迷茫运势最近几年一直不好,你给看看到底怎么了...
蛇生肖出生年份表,属蛇是2000年还是2001年的

蛇生肖出生年份表 十二生肖出生年份对照表【1924-2022 年】鼠的出生年份:1924、1936、194...
2022年牛年生男生女,2022年男女清宫表

2022年牛年生男生女 这段时间跟周围的宝妈聊天,不知怎么,聊着聊着就说到胎梦这件事,才发现...
龙的年龄表2022金命,1976年的龙45岁后的财运

龙的年龄表2022金命 干支纪年与五行关系 甲子【1924、1984】、乙丑【1925、1985】,海中金...
03年属羊女的和什么属相最配,鼠羊女和什么最配

03年属羊女的和什么属相最配说到属相相配,主要就看双方属相是否相合,一般合就吉,冲就不吉。...
巳时上等命最贵气时辰,丙火命是上等富贵命

巳时上等命最贵气时辰 子时(午夜11时~1时)女人在子时生是更好的,这是求都求不来的好事,这个...
生肖属相配对表图片,生肖配对表顺序

生肖属相配对表图片中国人大凡都知道,男女婚前需要合婚,否则恐怕婚后日子一塌糊涂,严重的还...
75年属兔女人的婚姻状况,75年兔女2022 年婚姻状况

75年属兔女人的婚姻状况 今天我们一起来看看属兔75年女婚姻状况 属兔女人的婚姻与爱情 ...
95属猪女生更佳配偶属相,1995女牛更佳配偶属相

95属猪女生更佳配偶属相 1995年属猪的更佳配偶会是谁?跟随小编一起来属相婚配了解了解吧!...
兔和牛的属相合不合结婚,男属牛女属兔相配吗

兔和牛的属相合不合结婚生肖鸡与生肖牛感情配对 肖牛与肖鸡的组合,此组合算是比较一般的...
51年生男2022年运程,71属猪的人十年大运

51年生男2022年运程 狮子男2022年运势详解,万事顺心,异性缘大旺,享受甜蜜的爱恋 进入2022 ...
属鼠最近一周运势,郑博士最新一周生肖运势

属鼠最近一周运势属性:鼠 本周运势使用时间:2022 年8月5日—2022 年8月11日 综合分析 五...
属羊的财运在哪个方向,属羊人今日偏财运方位

属羊的财运在哪个方向 羊年出生的人,为人善良,在生活中往往是属于人见人爱的人物。若能发...
黄历十二生肖日历表,2022 年日历带生肖

黄历十二生肖日历表 前言 2022 可谓是多灾之年,蔓延世界的疫情、非洲的蝗灾、全球粮食的...
- 数据加载中,请稍后...